基本简介
大数据特点
-
数据量大
-
种类多样
-
结构化:多指关系型数据库中,信用卡号码、日期、财务金额、电话号码、地址
-
半结构化:xml/json
-
非结构化:全文文本、图象、声音、影视、超媒体等信息。
-
-
应用价值高
大数据的作用
-
追溯:日志数据,定位问题;
-
监控:监控服务(可用性,QPS);监控具体业务,比如看双十一销售额;数据质量等等;
-
分析与洞察:toB业务,看板报表搭建;
数据分类
按照数据实效性(延迟情况):
-
离线:在今天(T)处理N天前的数据,常用的是今天处理昨天产出(T-1)的数据,也就是T+1地产出数据,延迟粒度为天
-
准实时:在当前小时,处理N小时前的数据,延迟粒度为小时
-
实时:在当前时刻处理当前的数据,延迟粒度为秒
数据处理链路(不严谨)
暂时无法在飞书文档外展示此内容
-
数据采集:数据的源头,从各种数据源中获取数据。分离线和实时采集,比如通过采集日志数据,实时采集到数据中间件中(mq)。
暂时无法在飞书文档外展示此内容
-
消息队列:Kafka & RocketMq
-
解耦:接口出现问题,不会影响当前功能
-
异步处理:不用所有流程走完再返回结果
-
流量削峰:流量高峰期,可以将数据暂放在消息队列中
-
-
消息代理:eventbus
-
事件总线,构建在消息队列之上的,围绕event构建一条虚拟总线,用户无需关注底层消息队列的细节(比如选型,多少分区,扩容,报警之类的),覆盖消息声明、发布、订阅、运维
-
-
-
数据处理:数据加工处理。
-
离线用hive,(近)实时用flink
-
数据同步:全量、增量同步
-
数据存储:将数据存到数据库中。
-
存储规范:数仓知识;数仓表的设计
数据服务:根据数据做一些应用。
离线处理(批处理)
个人学习路线
->首先接触Hive SQL,感觉和MySQL很像(DDL,DML,DQL语句)。学了一种数据库,其他的类SQL语法差不多。
->学了sqark参数相关的,优化任务执行
->再了解hadoop,spark原理
Hive
flink做流式计算,spark/hive做批式计算
简介:基于Hadoop的数仓管理工具,可以将HDFS上的文件映射为表结构。
架构
-
元数据存储
-
SQL到MapReduce的转换(sql解析)
注意:存储:hdfs;计算:mapReduce/Spark
Hive sql基础语法
参考:hive中文文档
常用的是创建 天级/小时级别表,分区为date/hour
-- 简单查询语句 select field1, field2 from db.table where date = '${date}' and hour = '${hour}' -- 聚合查询语句 select field1, sum(field2) as field2_alias from db.table where date = '${date}' and hour = '${hour}' group by field1 -- 临时查询 WITH subquery AS ( SELECT col1, col2 FROM db.table1 WHERE condition1 ) SELECT a.col1, a.col2, b.col3 FROM subquery a JOIN db.table2 b ON a.col1 = b.col3 WHERE condition2;
udf用户自定义函数
根据用户需求,自定义写函数处理数据
使用:用Java代码实现udf
step1:添加hive相关依赖
step2:编写udf类:继承UDF,并实现evalute方法
step3:项目编译,打jar包
step4:在hive中注册udf函数,并使用
package com.example; import org.apache.hadoop.hive.ql.exec.UDF; public class MyUDF extends UDF { public String evaluate(String input) { if (input == null) return null; // 在这里编写你的函数逻辑,例如把输入的字符串转成大写 return input.toUpperCase(); } }
Hadoop
分布式系统基础架构(主要是分布式存储和计算框架)
架构
-
存储:hdfs(hadoop distributed file system,分布式文件系统)
-
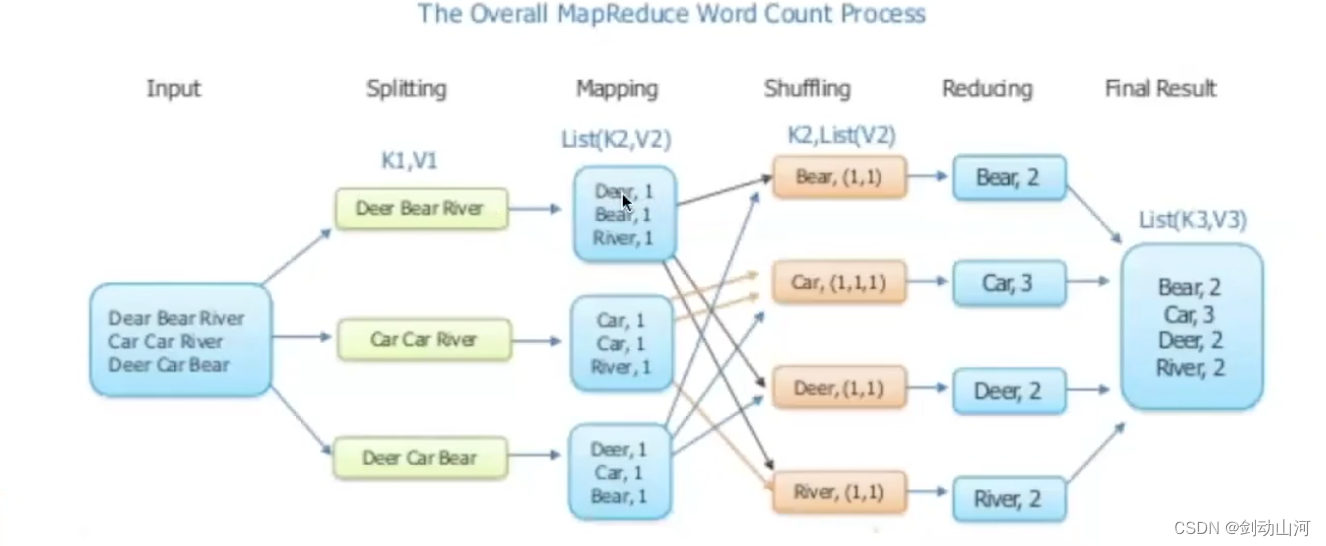
计算:mapReduce。将计算任务拆成map和reduce两个阶段,实际分成Map、Sort、Combine、Shuffle 以及Reduce 5个步骤
-
资源调度管理:yarn(cpu和memory)
Hadoop常用命令
Hadoop提供了shell命令来与hdfs交互:
hadoop fs -ls <path>:列出指定 HDFS 路径下的文件和目录 hadoop fs -mkdir <path>:在 HDFS 中创建新目录,类似于 Unix 的 mkdir 命令。 hadoop fs -put <localsrc> <dst>:将本地文件(或目录)复制到 HDFS,这与 FTP 命令 put 类似。 hadoop fs -get <src> <localdst>:将 HDFS 上的文件(或目录)复制到本地,这与 FTP 命令 get 类似。 hadoop fs -mv <src> <dst>:移动 HDFS 中的文件或目录,相当于 Unix 的 mv 命令。 hadoop fs -cp <src> <dst>:复制 HDFS 中的文件或目录,相当于 Unix 的 cp 命令。 hadoop fs -rm <path>:删除 HDFS 中的文件,类似于 Unix 的 rm 命令。 hadoop fs -cat <path>:在控制台显示 HDFS 文件的内容,类似于 Unix 的 cat 命令。 hadoop fs -du <path>:显示 HDFS 文件或目录的大小,类似于 Unix 的 du 命令。 hadoop fs -df <path>:显示 HDFS 的可用空间,类似于 Unix 的 df 命令
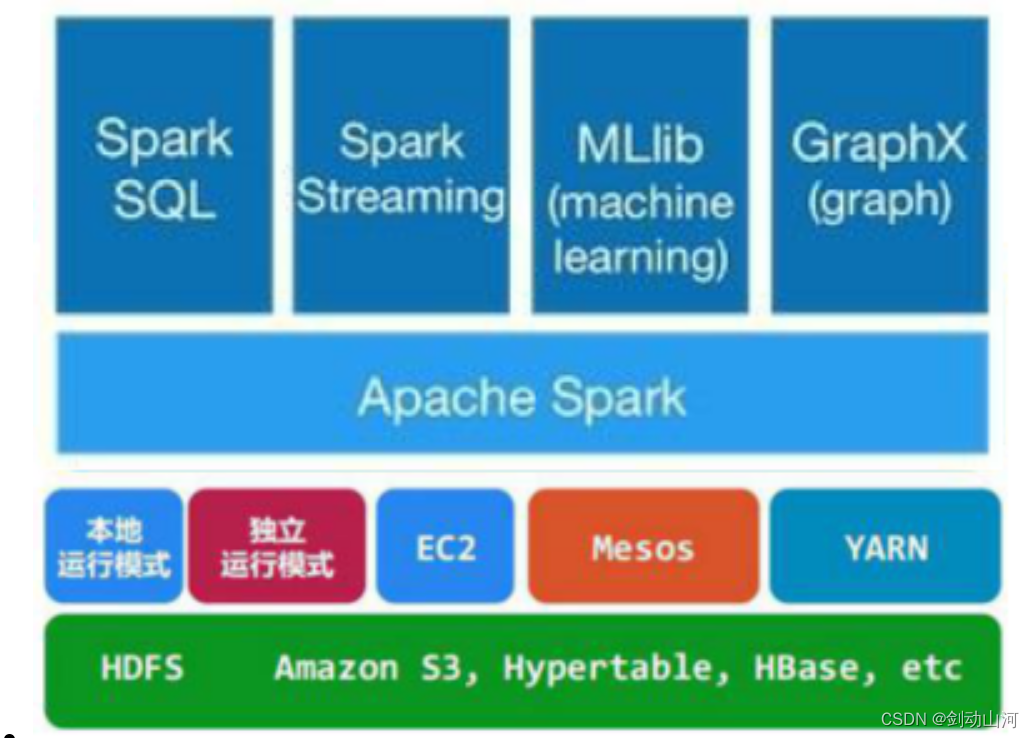
Spark
架构
使用成百上千台机器 并行处理 存储在离线表中的海量数据。海量数据的任务,拆成小任务,并发到每一台机器上处理。
计算引擎,支持离线(批)处理、流式
部署:可以继承到hadoop yarn上运行,也可以单独部署(目前只用过前者)
支持spark sql:变体的hive sql
性能比较:计算比mapReduce快
Spark sql基础语法
python的pyspark使用
-
启动一个spark client
-
查出你想要的数据
-
编写处理数据的逻辑并执行任务
from pyspark.sql import SparkSession from pyspark import SparkConf conf = SparkConf() conf.setMaster('yarn') conf.setAppName('hive_sql_query') spark = SparkSession \ .builder \ .config(conf=conf) \ .enableHiveSupport() \ .config("", "") \ .config("", "") \ .getOrCreate() # 查询语句 df = spark.sql("select field1 AS f1, field2 as f2 from table1")
Spark参数
master和worker
定义:物理节点
master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用。
worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
引用csdn链接:https://blog.csdn.net/hongmofang10/article/details/84587262?utm_source=app&app_version=4.15.2
driver和executor
driver:可运行在master/worker上;
作用:
-
main函数,构建SparkContext对象;
-
向集群申请spark所需要资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory;
-
然后开始调度、执行应用代码
executor:可运行在worker上(1:n)
作用:每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver。
常用参数
分配资源 内存参数 --每个execotr分配几个核心 set spark.executor.cores=4; --executor内存 set spark.executor.memory= 20g; --executor堆外内存 set spark.executor.memoryOverhead = 10g; --driver内存 set spark.driver.memory=25g; --driver堆外内存 set spark.driver.memoryOverhead = 10g; --任务推测机制相关 --开启推测机制(处理慢任务,尝试在其他节点去重启这些任务;加速整个应用的执行) set spark.speculation=true; -- 设置阈值 spark.speculation.multiplier=1.8 -- 设置分位数 spark.speculation..quantile=0.7 --坏节点黑明单(处理可能导致任务频繁失败的故障节点,当一个节点被列入黑名单后,Spark 调度器将不再在这个节点上调度任务,从而提高了作业的成功率和整体性能) set spark.blacklist.enabled = true 调整shuffle,数据倾斜,内存OOM,超时相关的,根据具体任务使用具体参数
在线处理(流式处理)
Flink
计算模式:流批一体
批计算:统一收集数据,存储到数据库中,然后对数据进行批量处理(离线计算)
流计算:对数据流进行实时处理(实时计算)
架构
三层架构:
-
API & Libraries层:提供了支持流计算DataStream API和和批计算DataSet API的接口
还有提供基于流处理的CEP(复杂事件处理库)、SQL&Table库和基于批处理的FlinkML(机器学习库)、Gelly(图处理库)等
-
Runtime核心层:负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。
-
物理部署层:该层主要涉及Flink的部署模式,目前Flink支持多种部署模式:本地、集群(Standalone/YARN
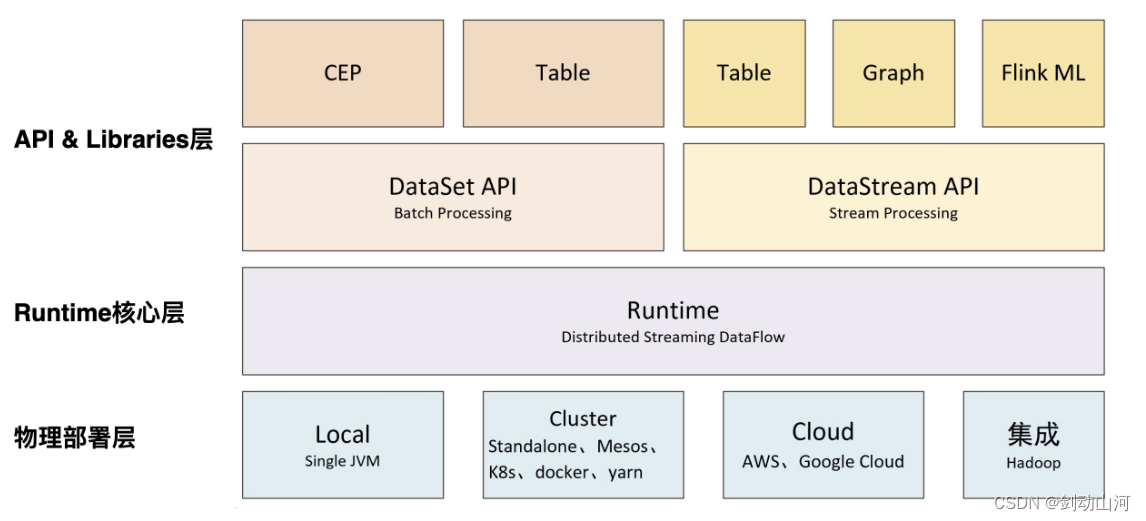
图片引用:https://blog.csdn.net/qq_35423154/article/details/113775546
运行时组件(任务调度)
4个组件(application url)
-
JobManager(任务管理器)
-
TaskManager(作业管理器)
-
ResourceManger(资源管理器)
-
Dispatcher(分发器)
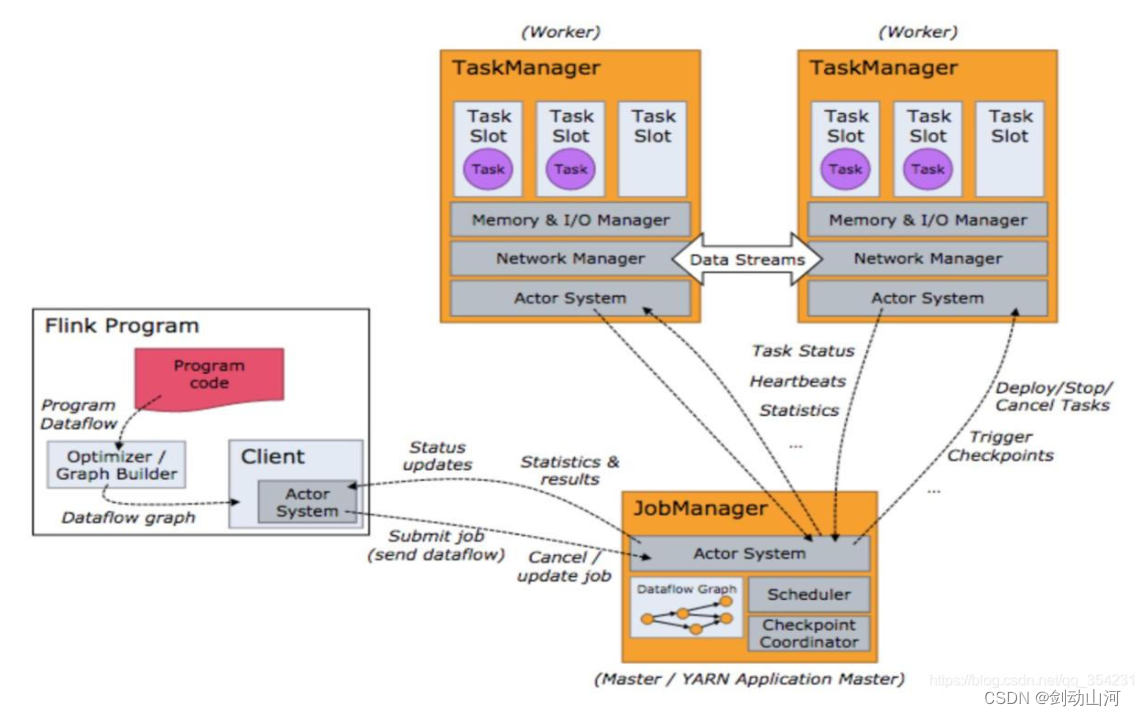
Flink sql基本语法
参考:flink中文文档
定义一个source,数据从哪里输入;定义一个sink,数据输出到哪里
create table data_source ( `user_id` string, `data` string) with ( 'connector' = 'rocketmq', 'scan.startup-mode' = 'latest', 'cluster' = '', 'topic' = '', 'group' = '', 'format' ='json', 'parallelism' = ‘9’ ); create table sink( user_id varchar, vv_cnt varchar, `start_window` TIMESTAMP, `end_window` TIMESTAMP ) with ( 'connector' = 'kafka-0.10', 'scan.startup.mode' = 'latest-offset', 'properties.cluster' = '', 'topic' = '', 'parallelism' = '5', 'format' ='json' ); INSERT INTO sink SELECT xx FROM feature_data_source where xx GROUP BY xx;
窗口计算
-
滚动窗口
-
滑动窗口
udf用户自定义函数
一些复杂的逻辑用户可以自定义处理
scalar function:输入,输出为标量
aggregation function:多行数据聚合成一行
table function:
数仓知识
数仓分层
将数据有序组织和存储起来,常见的数仓层级划分:
-
ODS层(数据引用层,operational data store):存放未经处理的原始数据,是数仓的数据准备区。
-
CDM层(数据公共层,common data model):完成数据加工与整合,是数仓最核心最关键的一层。
-
DIM(维度层):以维度作为建模驱动
-
DWD层(数据明细层):以业务过程作为建模驱动
-
常见的业务域:产商品域(产品product,商品goods,配置报价quote,合同contract),交易计费域(订单order,计量measure,计费billing,履约perform,票税invoice)
-
-
DWS层(数据汇总层):以业务主题作为建模驱动,根据DWD层数据,以各维度ID进行粗粒度汇总
-
-
ADS层(数据应用层,application data service):保存结果数据,为外部系统提供查询接口
其他分层结构
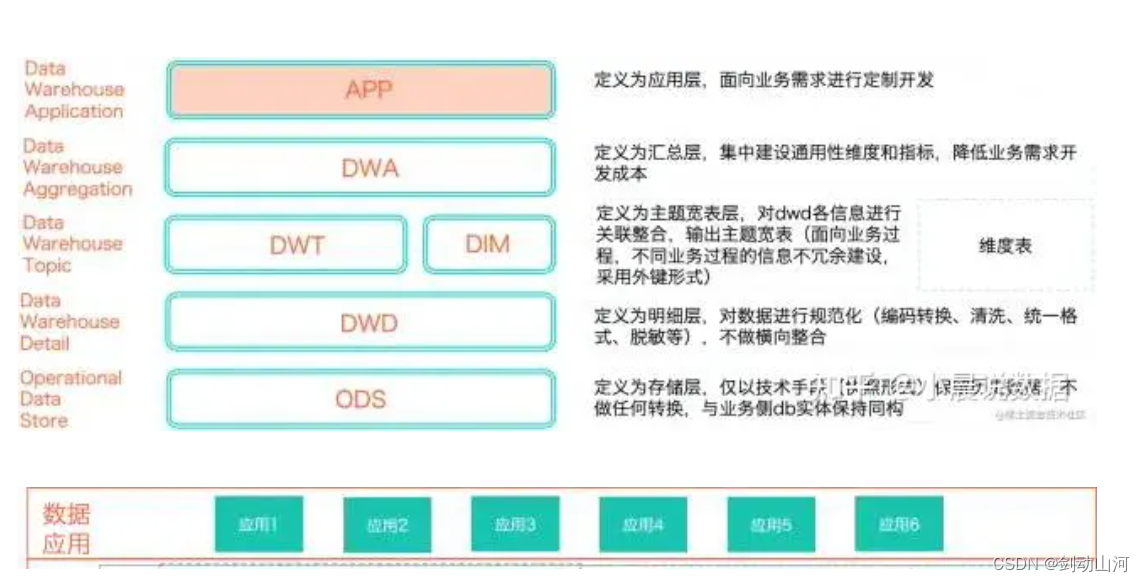
引用:知乎https://zhuanlan.zhihu.com/p/421081877
表命名规范
| 层名 | 命名规范 | 举例 |
| dwd | {层缩写}_{业务板块}_{数据域缩写}_{自定义表命名标签缩写}_{加载方式,天级/小时级,增量/全量} | dwd_sale_trd_item_di 交易信息事实增量表 |
| dws | {层缩写}_{业务板块}_{数据域缩写}_{自定义表命名标签缩写}_{统计时间周期范围缩写} | dwd_sale_trd_item_1h 交易信息事实1h增量表 |
总结
这部分学习,是边用边学,遇到问题就针对性地解决这个问题。这个过程学的很零散,需要定期将这些点连成线